Semantic Mapping for Wheelchair Navigation
Semantic Mapping for Wheelchair Navigation
Overview
In this project, I collaborated with the Assistive & Rehabilitation Robotics Laboratory (argallab) at Shirley Ryan AbilityLab to implement a semantic mapping system for a power wheelchair with a focus on enhancing user interaction and environmental awareness. This system utilizes a tablet to offer real-time feedback of the environment to the user. The feedback includes semantic labeling, which can be shown on the mapped environment when a landmark is identified through further inference. Additionally, for autonomous navigation towards a landmark, the user can initiate a plan by selecting it from the displayed landmarks. This approach aims to streamline the process of environmental interaction, making it more intuitive and user-friendly.
Hardware
- LUCI Wheelchair
- Intel RealSense D435i
- Windows Surface Pro 2 (with Ubuntu 22.04 LTS)
Software
- ROS 2 Humble
- SLAM Toolbox
- robot_localization
- Nav2
- YOLOv8
- Foxglove Studio
Any code related to LUCI was run within a Docker container.
Object Detection
I chose YOLOv8 for real-time object detection due to its superior performance in speed and accuracy. To integrate this, I developed a ROS 2 package specifically designed to run YOLOv8 using a RealSense D435i camera (available here). This camera was positioned adjacent to one of the LUCI cameras on the wheelchair. Notably, the RealSense camera was rotated 90 degrees counterclockwise, when viewed from behind, to align with the specific viewing angle. The critical decision to use an external RealSense camera was driven primarily by the unavailability of the LUCI camera streams in the software development kit (SDK) at the onset of this project phase. Given that the wheelchair’s built-in cameras are RealSense models that lack RGB sensors, I opted to employ an external RealSense D435i camera. By using its infrared (IR) streams, I was able to replicate the functionality of a LUCI camera, thereby circumventing the SDK limitations and ensuring compatibility with the existing system architecture.
I decided to focus on identifying doors and tables as they are pivotal landmarks for activities of daily living (ADLs), playing a crucial role in navigation and interaction within an indoor environment. To train the model, I created a custom dataset with several hand-labeled images of these objects. In the preprocessing phase, these images were converted to grayscale to align with the IR streams of the RealSense camera. To ensure the model’s robustness and generalizability, I applied various augmentations to the dataset, including rotation (to mimic different viewing angles), adjustments in saturation and brightness (to account for varying lighting conditions), and blur (to represent potential image quality variations). The dataset is available here. Below is a video of the custom-trained model:
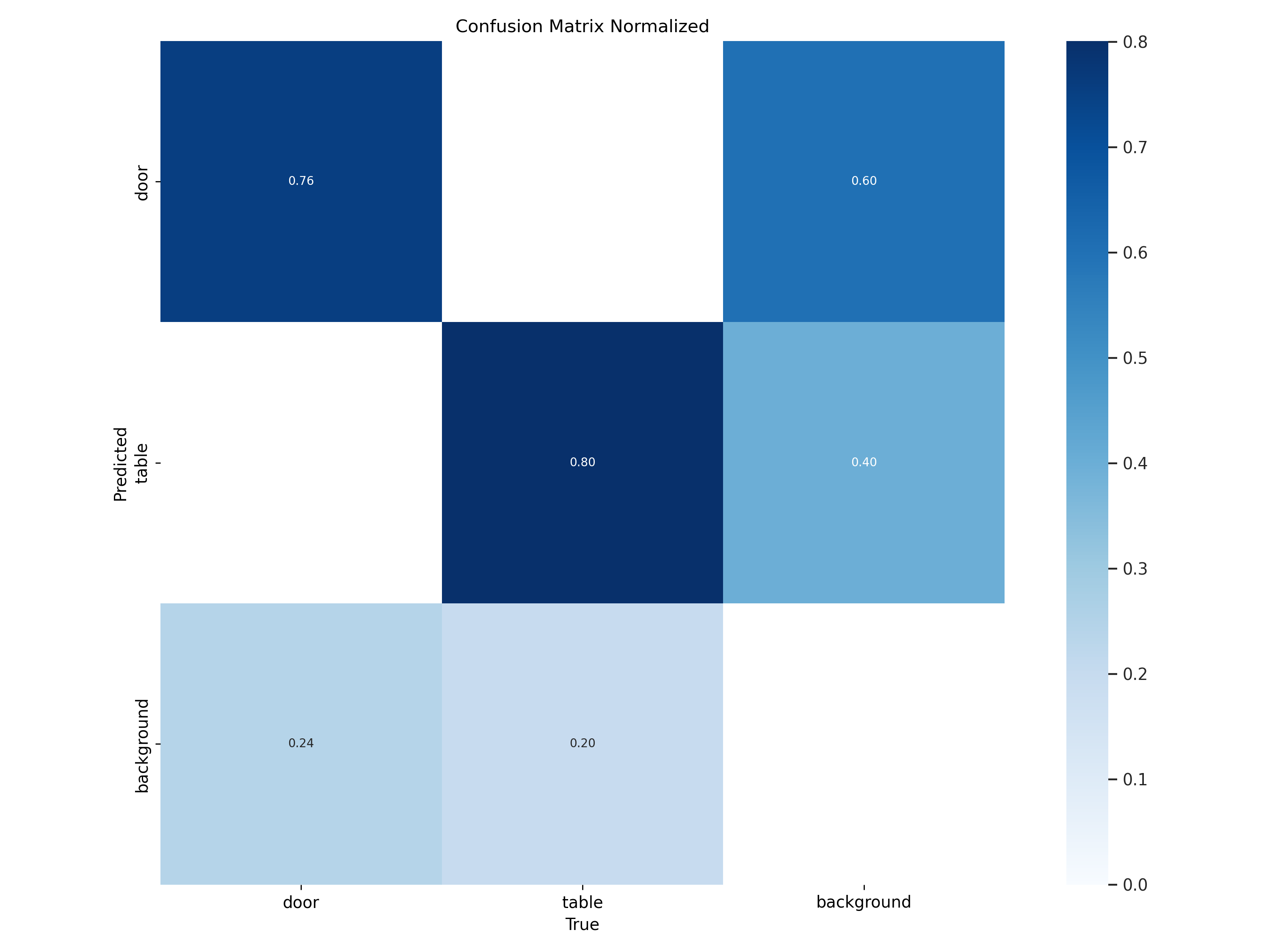
As shown in the normalized confusion matrix below, the model shows proficiency in recognizing tables with a true positive rate of 80%, demonstrating its solid detection capabilities for this category. The true positive rate for doors, at 76%, suggests a respectable recognition ability, although it is not as high as for tables. Meanwhile, background classification has a true positive rate of 60%, indicating room for improvement in distinguishing the background from other categories. Misclassification between doors and background stands at 24%, pointing to some confusion in the model, which can be an area for further training. The model’s ability to differentiate between tables and their surroundings, while adequate, could benefit from enhancements to reduce the 40% misclassification rate.
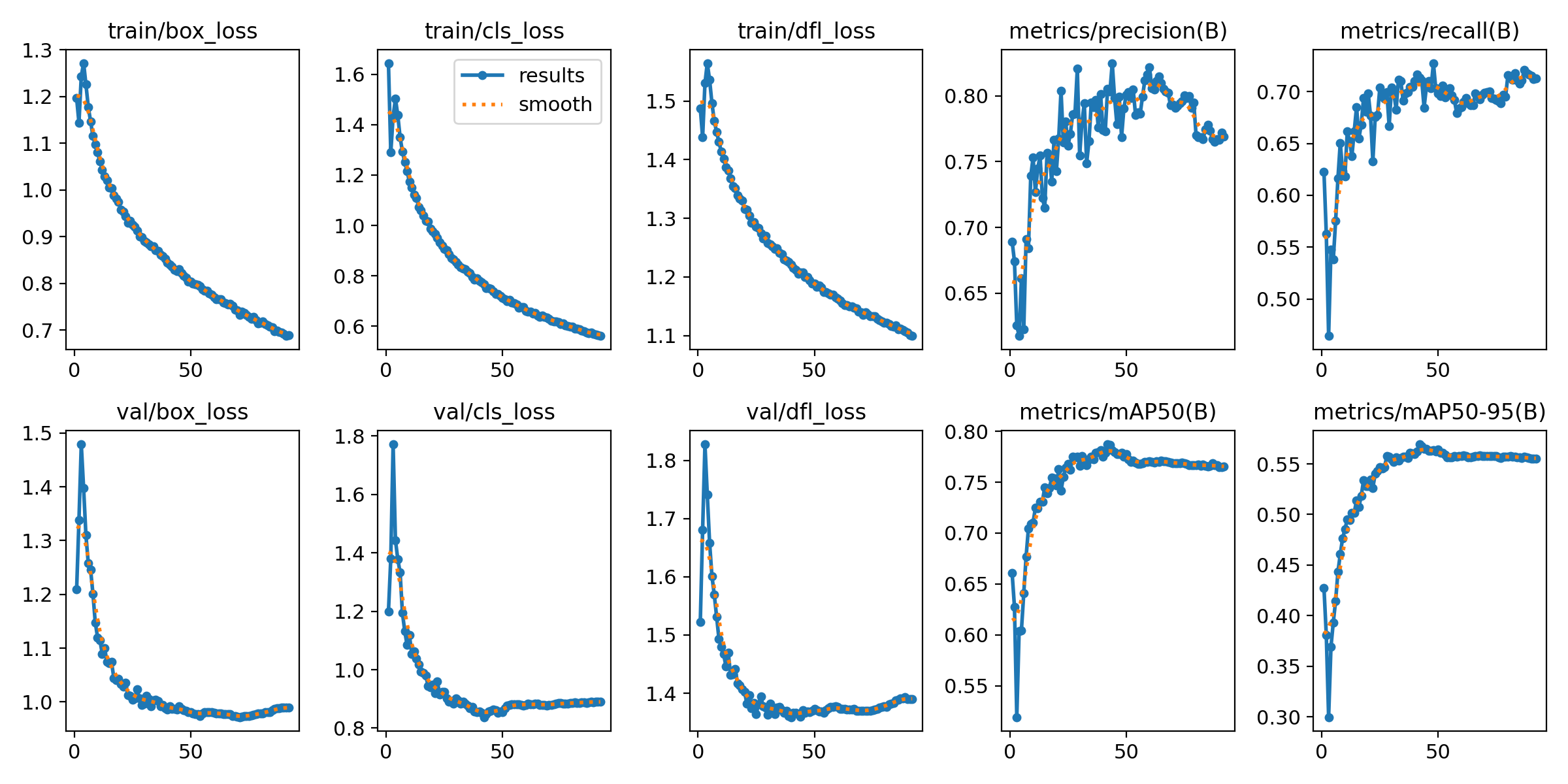
The model has demonstrated solid performance as reflected in its training metrics below. Over the course of training epochs, there has been a consistent decline in loss metrics—specifically bounding box loss, classification loss, and direction/feature loss—indicating effective learning in object localization and classification. The model’s precision at 0.805 and recall at 0.713 demonstrate its capability to correctly identify relevant objects and to locate a considerable number of positive instances. The mean average precision (mAP) scores provide further insight into the model’s localization accuracy, with an mAP of 0.787 at an intersection over union (IoU) threshold of 0.5, and a more modest score of 0.569 across a range of IoU thresholds from 0.5 to 0.95. These scores suggest that while the model is fairly effective in object localization, there is room for improvement, especially for applications requiring high precision. Nonetheless, the model is a promising tool for assisting wheelchair users in indoor environments, providing a reliable means to detect and localize important navigational landmarks.
Autonomous Navigation
For the autonomous navigation component of this project, three key packages were integrated: SLAM Toolbox, robot_localization, and Nav2. SLAM Toolbox was utilized for its efficient and versatile approach to simultaneous localization and mapping (SLAM), enabling LUCI to dynamically understand and map its environment. The robot_localization package provided a robust framework for fusing sensor data, ensuring accurate and consistent positioning within the mapped environment. Finally, Nav2 offered a comprehensive suite of navigation tools, allowing LUCI to plan paths, navigate around obstacles, and reach designated waypoints autonomously. The synergy between these packages created a sophisticated navigation system capable of guiding LUCI through indoor spaces safely and efficiently.
Navigation Graphical User Interface (GUI)
An intuitive and user-friendly GUI was developed to enhance the navigation of LUCI within indoor environments, designed for use on the Surface Pro 2 alongside the map displayed in Foxglove Studio. This GUI allows users to seamlessly interact with LUCI’s navigation system. It features capabilities such as saving landmarks detected in the environment, like doors and tables, and providing the option to cancel ongoing navigation commands with a simple button click, thereby ensuring a higher level of control and safety. The GUI presents these detected landmarks in a scrollable area, where users can select any landmark for saving.
Crucially, the GUI is closely integrated with a ROS 2 node, which underpins these navigational features. This node offers essential services that the GUI leverages; it handles the tasks of saving landmarks to a YAML file and canceling navigation commands to immediately halt LUCI’s movement. The save landmark service in the node ensures that landmarks are persistently stored, while the cancel navigation service provides a critical safety feature by allowing users to interrupt autonomous operations through the GUI. The integration of the GUI with the node, complemented by the map on Foxglove Studio displayed on the Surface Pro, ensures LUCI operates effectively and remains user-focused in its functionality.
Semantic Labeling
A semantic labeling pipeline was implemented to detect and label doors and tables within an indoor environment. The ROS 2 node developed for semantic labeling performs its task by publishing visualization markers for detected doors and tables. It obtains the real-world point coordinates for these objects from the YOLOv8 node, which are then processed to determine their precise location in the map.
Once a door or table is detected, the node transforms these points to the map frame, ensuring they are accurately placed in the environment’s spatial context. Unique identifiers are assigned to these points to avoid duplication and maintain clarity in the map. This process involves checking newly received points against previously identified ones, filtering out duplicates, and updating the existing markers if necessary.
The node publishes two types of markers - sphere markers, which visually represent the location of doors and tables, and text markers, which provide easy identification by labeling these points with names like ‘Door’ or ‘Table’ followed by their unique identifier.
Below are demo videos:
Future Work
- Object Detection Utilizing LUCI’s Camera: Integrate the LUCI camera system directly into the object detection pipeline
- Integration of GUI with Foxglove Studio: Embed the GUI into the Foxglove Studio environment to provide a unified visualization and control interface, improving user experience and system operability
- Expansion of the Training Dataset: Enrich the model’s training dataset with a wider variety of images capturing additional important landmarks for wheelchair users, such as ramps, elevators, and lifts, to broaden the model’s recognition capabilities
- Simplified Navigation Planning: Streamline the user interface for initiating autonomous navigation plans by reducing the steps required, possibly implementing single-tap commands that auto-calculate the orientation based on the destination
- Integration of Behavior Packages: Incorporate existing behavior packages developed by argallab, such as those for docking location identification and autonomous docking, to create a comprehensive suite of wheelchair navigation and interaction functionalities
Acknowledgements
I would like to thank the following people for all the help they provided for this project:
- Brenna Argall
- Matthew Elwin
- Andrew Thompson
- Larisa Loke
- Joel Goh